Elevated Error Rates
Postmortem
On Wednesday, October 12, Auth0 experienced an outage of our US authentication services. As a result of this outage, our subscribers experienced 57 minutes of downtime of services along with an additional 0.0007% of traffic dropped as we worked to restore services over 5 hours and 23 minutes. I would like to apologize to our subscribers for the impact to their daily operations as a result of this outage. Unplanned downtime of any length is unacceptable to us. In this case we fell short of both our customers’ expectations and our own. For that, I am truly sorry.
I would like to take a moment and explain what caused the outage, the resulting response from our team, and what we are doing to prevent events like this in the future.
Some Background
In our current US database architecture design, we leverage three different data centers to provide multiple levels of redundancy in the event of failure (illustrated below).
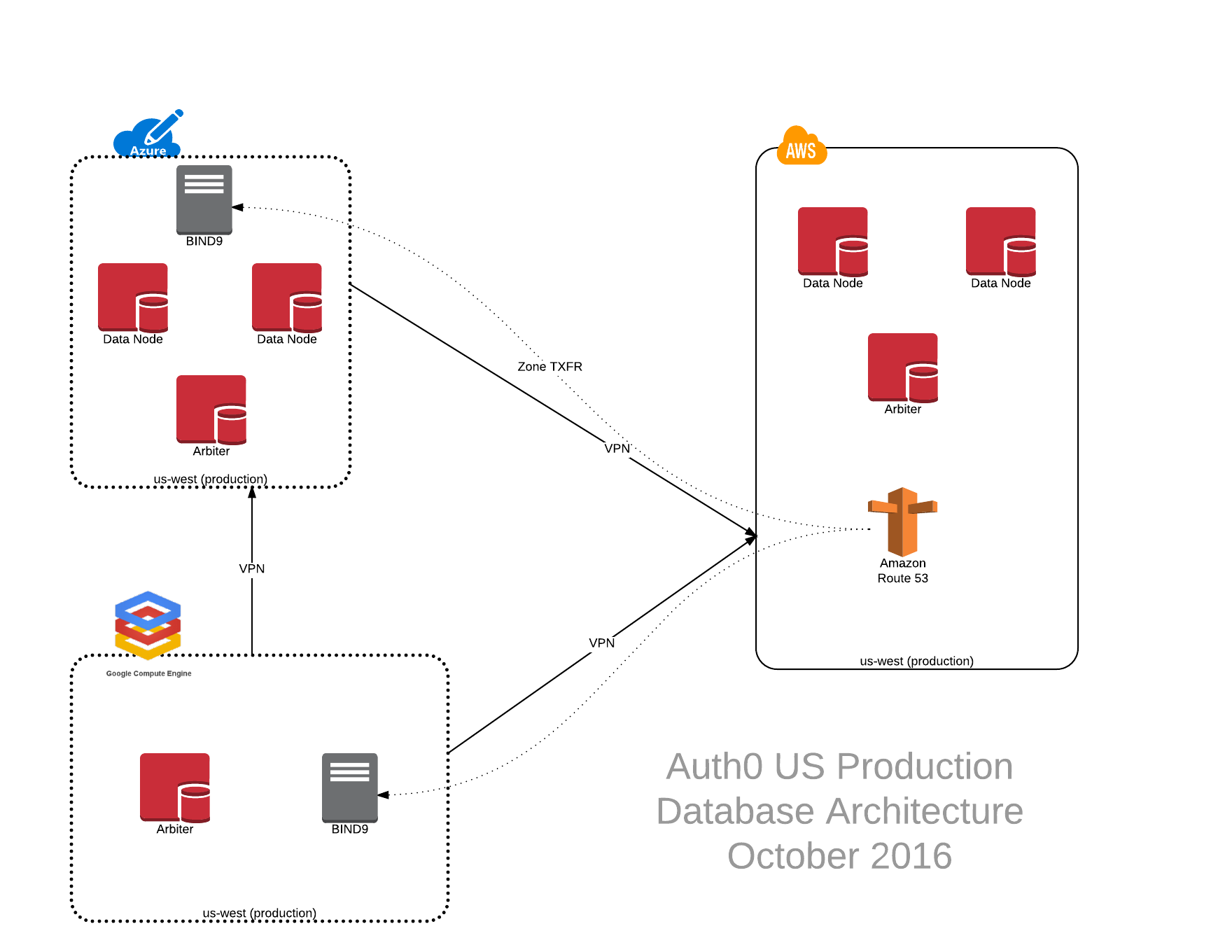
This design currently utilizes two data nodes and a single arbiter node at both our primary datacenter (AWS) and our secondary datacenter (Azure). In order to maintain data resiliency, our database technology (MongoDB) uses elections to determine which data node will be the primary database node (the only node in the cluster that can accept writes) and which nodes will be secondary nodes. There is also a third type of node role that we leverage called an arbiter. This node is able to participate in voting elections, however it does not store any data.
In the event that the primary database server has a failure and is unable to properly serve data, the cluster will initiate an election in order to vote and promote one of the existing secondary nodes to be a primary data node. The design includes the independent arbiter installation in our Google Datacenter (GCE). In the event of a network partition, the arbiter located in GCE is designed to monitor both AWS and Azure datacenters for failure. This design is intended to break any ties between the two datacenters, and thereby avoiding a split-brain scenario in the cluster. We have also weighted priorities on each node, preferring AWS before Azure to minimize latency.
DNS for this solution is hosted in a private zone provided by AWS Route 53. In order to avoid a dependency on DNS, the zone data is replicated at each datacenter in the event that VPN links are abruptly terminated. To facilitate this, a job runs every few minutes in both the Azure and GCE data centers to refresh the DNS zone data and make it available to local BIND9 nodes for serving.
What Happened
On October 12 at 05:19 UTC, our VPN endpoint in AWS suffered from memory exhaustion, and momentarily dropped incoming IPSEC packets from our Azure and GCE sites. This condition cleared within a second, and the connection was re-established automatically via configured keepalive setting.
During this period of time, the primary database server in AWS was expecting a heartbeat response from the cluster members located in Azure. As a result of the connectivity loss, the primary database server failed to receive the necessary heartbeat packets and marked itself as unhealthy. This triggered the primary database to step down and cease to be the primary server in order to force a cluster election.
Our response team arrived at 05:21 UTC and found all members of the database cluster in a SECONDARY state and began troubleshooting. Over the next several minutes, the team was unsuccessful in forcing promotion of a data node in either the AWS or Azure data centers. The GCE database arbiter was actively vetoing the promotion of AWS data nodes to primary, and arbiters in AWS were actively blocking the promotion of Azure nodes to primary. The database nodes in AWS were temporarily taken offline to prevent veto voting from occurring, and was sufficient to force the election of the primary database server in Azure. This was completed at 06:12 UTC. At this time, authentication services in Azure began responding to requests and error conditions began subsiding.
Once the service state returned to a working state, the team once again attempted to move the primary database role back to AWS from Azure. This again triggered the veto loop and services again were dropped for approximately two minutes while the team recovered the database in the same fashion previously. Over the course of the next few hours, the response team continued to attempt to roll back traffic to the primary data center in AWS. Each election event would result in the arbiter node in the Google data center again actively vetoing attempts to promote nodes in the AWS datacenter.
After further discovery, the response team found that the arbiter node in the Google data center was unable to connect to any of the database nodes in the AWS data center, and as a result considered those nodes UNHEALTHY. This resulted in the arbiter issuing vetoes anytime an AWS node was elected as it could not independently verify their health. The response team found that DNS requests for the IP addresses of the database servers in AWS were going unanswered. Upon further investigation, the response team found that the BIND9 DNS server actively refused to load up the internal zone data due to an incorrectly formatted DNS record. Once the team removed the offending record from the zone, the DNS server successfully loaded the internal DNS zone and was able to properly resolve the address for the database servers in AWS. This was completed at 11:35 UTC. Shortly afterward, the response team was able to successfully elect one of the database nodes in AWS without a veto from the Google arbiter, and transparently moved traffic back from Azure to AWS where it continues to run.
What we’re doing about it…
This problem uncovered quite a bit about our infrastructure that we have been critically reviewing over the last 36 hours. We will be aggressively implementing the following remediation over the coming weeks:
- We will be reviewing our VPN infrastructure to add additional capacity. The originating event in this incident was a result of memory exhaustion of our main VPN server. We will be reviewing the profile of that machine to ensure it is adequately sized for the load it is currently handling. In addition, we will be adding secondary VPN paths to ensure that we have resiliency in network connectivity between our data centers in the event of future network events. We will also be ensuring we have alerts properly configured to alert us in the event of future memory on this node and across our fleet as a whole.
Status: Completed We will be reviewing and simplifying our DNS stack. We learned that the version of BIND9 DNS server we have deployed strictly enforced (RFC1034 and RFC1035). In this implementation, underscores (
_) are only to be used on SRV and TXT records to clearly delineate various namespaces. The DNS implementation used in Route 53 is less strict than BIND9 DNS server, relying on RFC2181, which is significantly less strict than the original RFCs and allows records with underscores (_) to be used on A records. In the immediate term, we have removed the Route 53 -> BIND9 DNS zone sync, and instead rely on/etc/hostsrecords.
Status: Completed
Added a monitoring alert whenever the bind process fails.
Added a monitoring alert whenever the sync process fails.
Sync process fails leaves the previously synchronized records in place rather than clearing.We will be refactoring our provisioning process. The DNS record in question that contained underscores was an orphaned DNS record. Whenever a new host is provisioned, DNS records are added automatically as part of a Dynamic DNS process we have setup. When a host is de-provisioned, records are not automatically purged. We want to ensure that we do not leave stale DNS records around. Had these records been properly purged, it is possible that the arbiter would not have had connectivity issues leading to the vetoes.
Status: Completed
Script identifying orphaned records.We will be upgrading and reconfiguring all of our database clusters to leverage the new RAFT protocol in MongoDB * v3.2. This new mechanism no longer uses voting and vetoes to elect a master, rather relying on consensus via RAFT. When reproducing this issue in our lab, we found that the cluster was significantly better protected in the scenario we experienced, and will be rolling it out to our production clusters to add additional resiliency.
Status: CompletedWe will be updating the service to automatically retry at least one minute after failure to connect. What we found is that some of our logging services would terminate due to lack of connectivity and would not automatically restart. We will be adding additional monitoring to alert us on several of the error conditions that we ran into during this event. After the fact, we learned that the error logs being thrown showed that arbiter would veto various elections. This was logged with an error that told us elected node was not up-to-date and that there was a newer copy of data on another node in the cluster. We learned during our discovery that the arbiter in GCE was actively vetoing elections for nodes is AWS because it was unable to resolve nodes due to DNS failures, the arbiter in AWS was actively vetoing elections for nodes in Azure because it saw higher priority nodes in AWS, and that the arbiters in Azure were vetoing elections in Azure because it saw nodes in AWS with higher priority. In addition to ensuring the logging service is running, we will be adding additional monitoring to our logging infrastructure to watch for key events in the future, including veto events and heartbeat failures.
Status: CompletedWe will be reviewing our failover plan for all infrastructure components, and begin holding exercises to practice common failure scenarios. In this incident, our team focused on trying to restore services to AWS for the first half of the initial outage before attempting to failover to the Azure immediately. We will be creating concrete process to help guide first responders to restore service as soon as possible, and will be facilitating table-top failure exercises for our components. In addition, we will be re-introducing Chaos Monkey techniques to our infrastructure, first starting with development and test environments and eventually re-introducing into the production environment. The goal here would be to document and understand as many failure scenarios as we can plan for, and test out our resiliency of our platform.
Status: Completed
We failed an availability zone in the AU region.
We have reserved team time every 3rd iteration to spend on failure analysis and practice.Finally, we will be re-building this architecture to remove both Azure and GCE from our current architecture and leverage only AWS. Resources in the Azure datacenter will be re-provisioned in AWS east datacenters, and the arbiter in GCE will be moved to a third US region provided by AWS. This work has been underway for well over a quarter, with the primary goal of reducing overall operational complexity with toolset consolidation. Many of the action items addressed above have been carefully considered and will be automated in our new infrastructure, including logging and alerting improvements. In the short term, we will continue to address the action items listed above. In the long term, many of the missing alerting items will be baked into our provisioning process for free ensuring we have uniform visibility across our fleet. We expect the replacement database cluster to be in place to begin comprehensive load tests and validating metrics collection prior to removing database nodes from Azure.
Status: In Progress
Move to a single cloud strategy (estimated 2/10/2017).
Summary
We realize that Auth0 is a critical part of your development and production infrastructure. Again, I would like to take a moment to apologize for the impact that this outage had on your operations. We are deeply aware of the pains that you and your subscribers feel as a result of downtime. Issues like the one described above only harden our resolve to provide you with the most safe and stable way to authenticate, and to respect the trust you have placed with us. Our teams continue to work tirelessly to provide you with the best authentication experience possible.
Thank you for your continued support of Auth0.
James Fryman
Infrastructure Product Owner
Resolved
Monitoring
Identified
Monitoring
Identified
Guardian (MFA) is now available.